1.大数据是什么
顾名思义大数据就是指大量的数据,大数据技术一般包括采集、处理(批处理/流处理)、存储、分析、应用。通常大数据会有以下5个特点(大数据的5个"V"):
Volume:指数据量大。数据的单位从我们熟悉的MB,GB,TB已经到了PB、ZB等。
Velocity:指数据产生速度快。想象一下,在原来只采集一栋楼宇的电量用度、温度变化时一天可能只会有少量的数据,现在随着发展在整个城市中都部署有大量的采集器,这时候数据的生成就不是一开始的时候可以想到的了,也不能通过传统的系统再去采集这么大量的数据。
Veracity:指数据真实性。大量的数据可能会出现由于人为因素、环境因素等采集到一些异常的数据,这种情况下就需要对异常数据进行校验、清洗,保障数据的真实性。
Value:指数据价值。我们对采集到大量的数据进行建模分析,从中挖掘更深层的价值,比如通过对某地近两年来河流的水流量采集可以更好的预测汛期,发出更精准的预警,从而避免造成损失。
Variety:指数据类型繁多。随着发展可能由原来单一的结构化的数据变化为多样的数据,比如说通过摄像头采集到的视频信息、通过用户通过不同途径上传的文件等。
大数据具有更大的数据量、更快的速度、更多的数据类型等特点。在一定的数据真实性基础上,大数据技术最终要为数据背后的价值服务。
2.Hadoop是什么
Hadoop是一个开源的、高可靠、高扩展、高容错、高效的分布式计算和存储框架。主要用来解决大量数据的存储和分析计算的问题。
下面我们通过对Hadoop的核心组件介绍来了解Hadoop到底是什么。
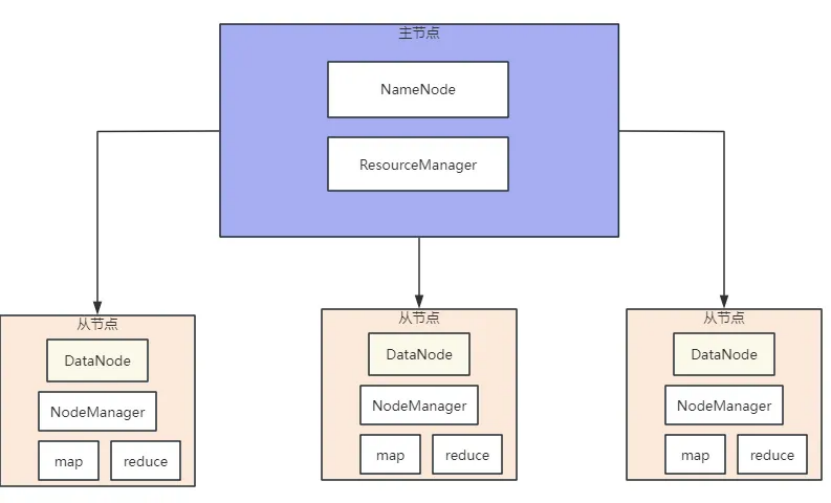
2.1 HDFS
HDFS(Hadoop Distributed File System)是一个分布式文件系统。
分布式:将大量的文件分批存储到大量的服务器上,以便于采取分而治之的方式对海量数据进行计算分析;
文件系统:用于存储文件,通过文件的元数据信息来定位文件的具体位置。
2.1.1 HDFS架构概述:
2.1.1.1 NameNode:
负责存储文件的元数据,如文件名、文件目录结构、文件属性(创建时间、地址、副本数、权限),以及每个文件的块列表和块所在的DataNode等。
2.1.1.2 DataNode:
负责在本地文件系统中存储文件的具体内容。
2.1.1.3 SecondaryNameNode(2NN):
负责定时对NameNode的元数据进行备份。
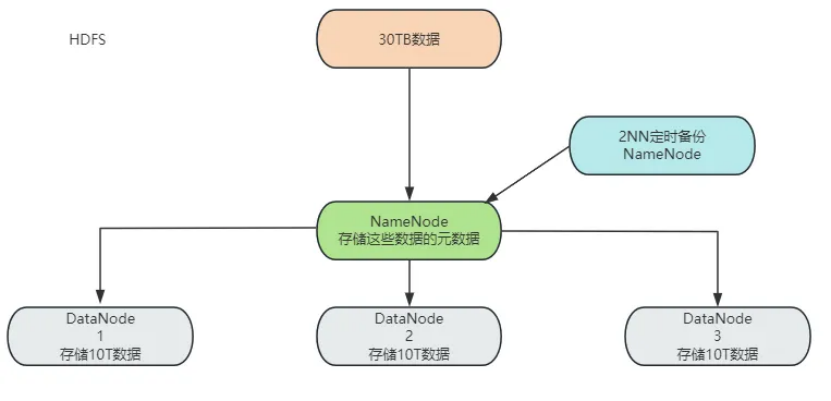
2.1.2 HDFS的缺点:
不适合存储大量小文件
占用NameNode大量的内存来存储文件的元数据,小文件存储的寻址时间超过读取时间。
不适合低延时数据访问
不能像MySQL那样对数据的可以实时访问。
不支持并发写入、文件随机修改
一个文件在同一时刻只允许一个写操作,不允许多个线程同时修改,对文件只支持追加,不可以删除。
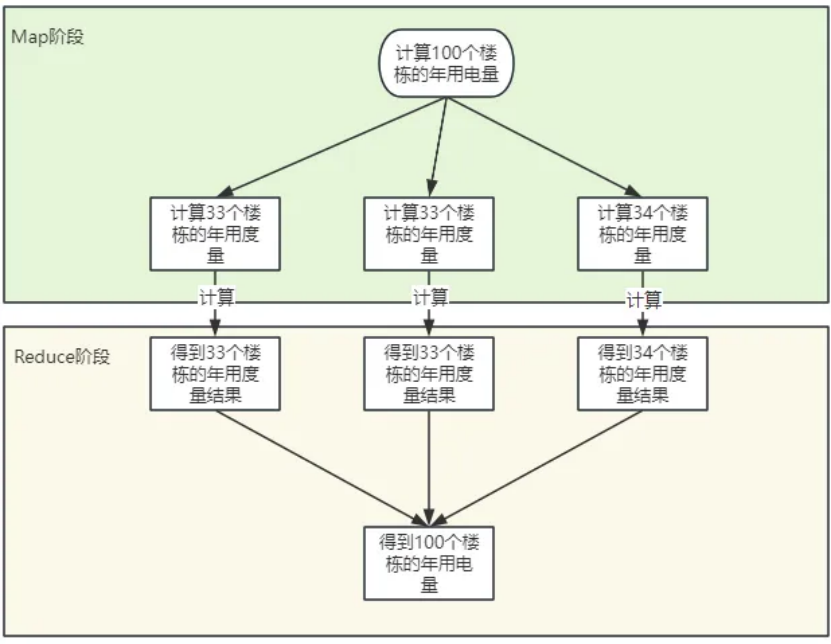
2.2 MapReduce
使用集群进行计算的方式被称为分布式计算,MapReduce是Hadoop中一个分布式计算的组件。
2.2.1 MapReduce架构概述:
MapReduce将计算过程分为两个阶段:Map和Reduce。
Map阶段并行计算客户端输入的数据。
Reduce阶段对Map阶段计算得到的结果进行汇总。
2.3 YARN
YARN(YetAnotherResourceNegotiator)是资源协调者,是Hadoop的资源管理器。
2.3.1 YARN架构概述:
2.3.1.1 ResourceManager(RM):
负责整个集群的资源调度。
2.3.1.2 NodeManager(NM):
负责单个节点服务器的资源调度。
2.3.1.3 Container:
容器,相当于一台独立的服务器,里面封装了任务运行所需的资源。
2.3.1.4 ApplicationMaster(AM):
负责对单个任务运行期间的资源调度。
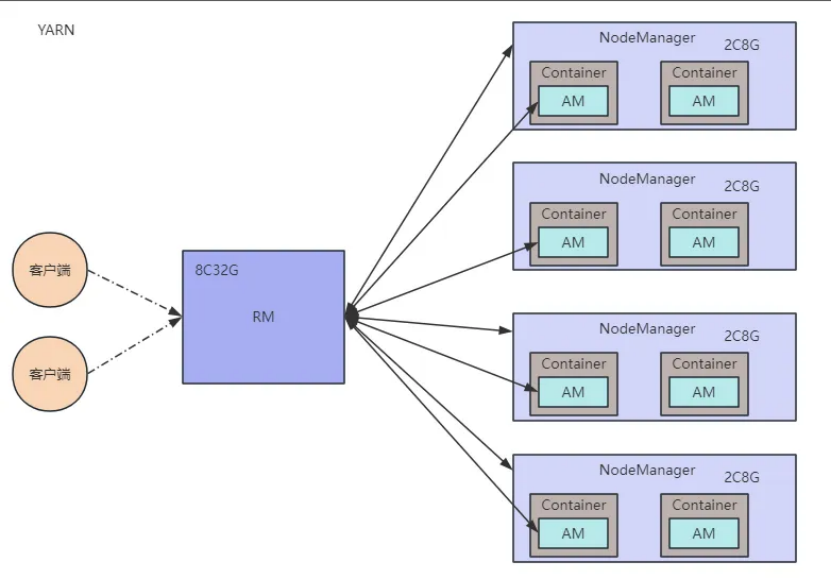
2.4 三个组件的关系