一、为什么需要流计算
随着工业4.0时代的到来,工业物联网(Industrial Internet of Things, IIoT)已经成为制造业转型升级的关键驱动力。工业物联网通过连接各类传感器、设备和系统,实现了设备间的数据交流和共享,极大地提高了生产效率、降低了运营成本,并为企业带来了前所未有的商业价值。然而,这一过程中产生了海量的实时数据,对数据处理的速度和效率提出了极高的要求。高性能流式计算因此成为了工业物联网领域不可或缺的技术手段。
二、工业物联网流式数据的特点
工业物联网数据与其他业务的流式数据不同,其具有以下特点:
1、海量数据:工业物联网环境中部署了大量的传感器和设备,这些设备不断产生数据,导致数据量极其庞大。
2、高并发:由于设备数量众多,数据产生速度快,系统需要处理高并发数据流,尤其是在生产线或自动化控制系统中。
3、实时性要求高:工业物联网应用通常对数据的实时性有很高的要求,如实时监控、实时决策支持等,以确保生产安全和效率。
4、多样性:数据类型多样,包括温度、压力、速度、位置等多种传感器数据,以及视频、音频等多媒体数据。
5、异构性:设备和系统的多样性导致数据格式和协议的异构性,需要系统具备处理不同格式和协议数据的能力。
6、价值密度低:由于数据量大,并非所有数据都具备同等的价值,如何从海量的数据中提取有价值的信息是一大挑战。
三、工业物联网带来的挑战
高并发和海量数据对计算资源的处理能力提出了极高的要求,流式计算系统需要能够快速、高效地处理这些数据。在保证处理速度的同时,系统还需要保证数据处理的精确一次性和状态一致性,以避免错误决策。工业物联网环境中的数据流可能随时间变化,系统需要能够动态适应数据流的变化,如突发流量或数据速率的变化。
在保证实时性和处理能力的同时,系统还需要高效地管理和调度计算资源,以优化成本和提升效率。由于工业物联网系统的连续运行要求,系统需要具备强大的容错机制,确保在发生故障时能够快速恢复,不影响生产。数据的异构性和多样性要求流式计算系统具备强大的数据整合和清洗能力,以统一数据格式并提供高质量的数据分析基础。

在众多流式计算框架中,Apache Flink以其卓越的性能、灵活的API设计和精确一次的状态一致性保证等特点,成为了工业物联网进行高性能流式计算的首选技术。Flink不仅仅能够处理实时的数据流,还能在需要时对历史数据进行批处理,完美适应了工业物联网场景中对于实时性和数据处理多样性的需求。
四、Apache Flink的优势
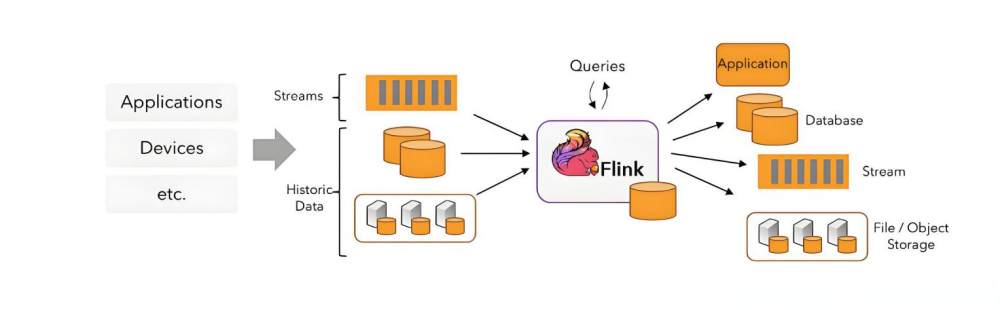
1、统一的流处理和批处理
Flink 提供了统一的运行环境和API,既可以处理无界流数据,也可以处理有界数据集,这使得开发者在处理不同类型数据时无需切换到不同的系统。
2、精确一次的状态一致性保证
Flink 提供了强大的状态管理和容错机制,确保即使在发生故障的情况下也能保证状态的一致性,这对于需要准确数据结果的工业物联网应用至关重要。
3、事件时间处理
Flink 支持基于事件时间的处理,允许开发者按照数据产生的时间顺序进行计算,这对于处理时序数据和确保事件处理的准确性非常重要。
4、高吞吐量和低延迟
Flink 采用了优化的执行引擎和内存管理机制,能够在保证高吞吐量的同时,实现低延迟的数据处理。
5、动态缩放和故障恢复
Flink 支持在运行时动态调整资源,同时提供了快速的故障恢复机制,保证了系统的稳定性和可靠性。
6、丰富的生态系统
Flink 拥有丰富的连接器、库和API,支持与各种数据存储系统的集成,如Apache Kafka、HDFS、Elasticsearch等。
五、Flink在工业物联网中如何应用
Apache Flink 在工业物联网领域中的应用,主要集中在设备监控和预测性维护两大场景。在设备监控方面,Flink 利用其高效的流处理能力,通过工业物联网统一接入系统实时传来的设备数据,为企业的生产运营提供实时反馈。通过对温度、湿度、压力等关键参数的实时监测,Flink 能够及时发现设备异常,预警潜在风险,从而确保生产过程的稳定性。
在预测性维护方面,Flink 结合机器学习算法,对设备的实时数据和历史数据进行深入挖掘,预测设备可能出现的故障。这一应用场景为企业带来了显著的优势,通过提前制定维护计划,企业可以避免计划外的停机,降低维护成本,提高设备的运行效率。
同时,Flink 还在工业物联网中发挥着构建实时数据管道和ETL流程的作用,为事件驱动的自动化决策提供支持。这使得企业能够实时处理生产过程中的各类数据,快速做出决策,进一步优化生产流程。
六、Flink高性能流式计算原理
Flink的高性能流式计算背后是一套复杂的技术架构,它融合了多种技术创新来优化数据处理速度和效率。
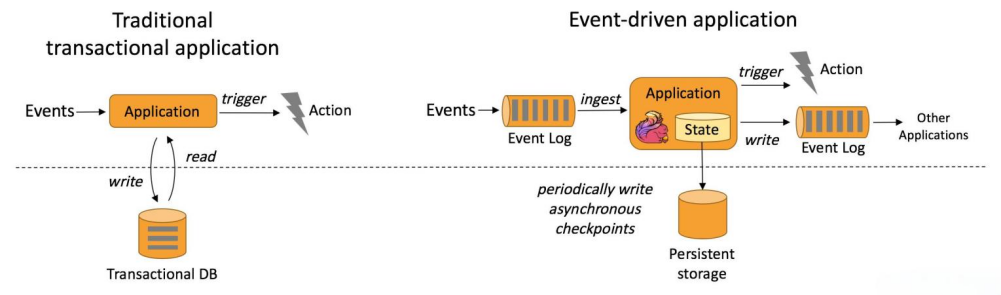
首先,在数据模型方面,Flink通过其核心的DataStream API支持流处理,该API基于轻量级的分布式快照算法,可以在保持状态一致性的同时,实现对无界流数据的实时处理。此外,Flink的DataSet API支持批量数据处理,但底层仍然使用流处理引擎,使得批处理作业能够享受到流处理的低延迟特性。
在事件时间与处理时间的处理上,Flink引入了水印(Watermarks)和时间窗口(Time Window)的概念,允许用户在事件时间语义下进行计算,即使在数据乱序到达的情况下也能保证结果的准确性。水印的传递和窗口的计算都是基于Flink的内部机制,这些机制最小化了事件时间的处理延迟,并确保了事件按照其原始时间顺序被处理。
状态管理方面,Flink提供了可扩展的内存状态后端和可选的RocksDB状态后端,以支持大规模的状态存储需求。Flink的检查点机制和两阶段提交协议确保了即使在失败的情况下也能实现状态的精确一次语义。这种设计允许系统在保持高吞吐量的同时,还能提供强一致性的状态管理和容错能力。
七、结语
Apache Flink在工业物联网场景中展现出高性能流式计算的巨大潜力。配合研博工业物联网统一接入系统,Flink在工业物联网领域展现出了卓越的数据处理能力和实时分析优势。这不仅为企业提供了更加精准的数据洞察,还极大提升了生产效率和运营决策的速度。随着工业物联网技术的不断演进,Flink将继续在企业中扮演着核心角色,推动流式计算技术在工业领域的广泛应用。
























