随着第四次工业革命的推进,工业物联网(IIoT)已经成为推动制造业革新和转型的重要力量。通过整合多种传感器、设备和系统,工业物联网实现了设备数据的有效流通和共享,极大促进了生产效率的提升和运营成本的降低,同时也为企业创造了前所未有的商业机会。但是,这一技术进步也带来了巨大的实时数据量,对数据处理的速度和效率提出了极高的挑战。在这种背景下,高性能的流式计算技术成为了工业物联网领域必不可少的核心技术。

在众多流式计算框架中,Apache Flink以其出色的性能表现、灵活的API设计以及精确的一次性状态一致性保证等特性,赢得了工业物联网领域进行高性能流式计算的青睐。Flink不仅能够高效处理实时数据流,还能够根据需要对历史数据进行批处理,完美匹配工业物联网在实时性和数据处理多样性方面的需求。
它们的区别主要在于集群的生命周期以及资源的分配方式不同,以及应用的main方法到在客户端(Client)执行还是在JobManager执行。
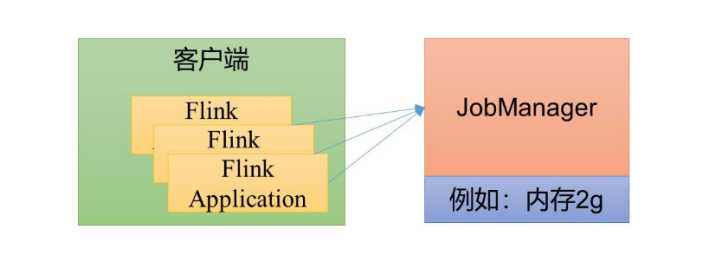
在Flink中,采用会话模式更贴合我们常规的操作逻辑。在这种模式下,我们首先建立并激活一个集群,保持一个持续的会话状态。用户可以通过客户端向这个活跃的会话提交作业。由于集群在启动时资源便已分配完毕,因此提交的各个作业将争夺集群内有限的资源。这种模式主要适用于管理和执行众多小型且执行周期短的作业。
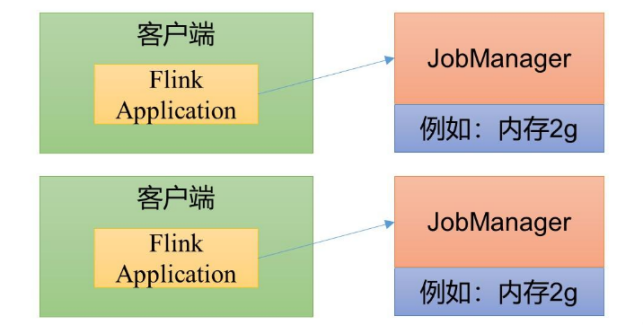
在单作业模式中,作业提交之前,Flink集群保持静止状态。作业提交时,客户端负责将任务代码传递给JobManager进行调度执行。鉴于会话模式中资源共用可能引发的一系列问题,我们可以转为采用单作业模式,即为每个提交的作业单独创建并启动一个集群。在这种模式下,作业执行结束,集群随即停止运作,同时释放所有分配的资源。
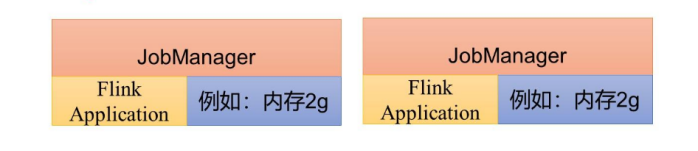
在提交作业时,Flink集群随之启动,但在此过程中摒弃了客户端的角色。作业不是通过客户端提交给JobManager,而是直接将应用程序提交到JobManager上进行运行。在之前提到的会话模式和单作业模式中,应用代码在客户端执行,并由客户端负责将代码发送至JobManager,这往往会导致客户端所在节点承受较大的网络带宽压力,尤其是在下载依赖和传输二进制数据时。此外,如果多个作业使用同一客户端提交,还会进一步增加该节点资源的负担。
为了解决这个问题,Flink提供了无客户端的方式,直接将应用程序部署到JobManager上执行。这意味着每个提交的应用程序都将启动一个独立的JobManager,从而构建一个专用的集群。这个JobManager仅为了运行该单一应用程序而存在,并在应用程序执行完成后关闭。这种模式被称为应用模式。
在应用模式与单作业模式中,都是在作业提交后创建集群。不同之处在于,单作业模式依然依赖于客户端提交作业,每个作业由客户端解析后分配一个独立的集群;而在应用模式中,作业直接由JobManager执行,无需通过客户端中转,每个应用程序都对应一个专门启动的JobManager。
六、Flink部署运行
使用yarn做资源管理,分别使用以上三种模式部署任务:
特点:先启动flink集群,提交作业时动态分配资源(TaskManager和slot),取消作业时资源被回收
1)启动Flink集群
bin/yarn-session.sh -d -nm yanboot-iot
参数说明:-d 分离模式 -nm 任务名称
启动之后会给出一个管理页面地址以及一个YARN应用ID
2)提交作业
bin/flink run -c com.yanboot.iot.DeviceDataCount FlinkTutorial-1.0-SNAPSHOT.jar
特点:提交作业后启动flink集群
bin/flink run -t yarn-per-job -c com.yanboot.iot.DeviceDataCount FlinkTutorial-1.0-SNAPSHOT.jar
特点:用户的代码在jobManager端解析
bin/flink run-application -t yarn-application -c com.yanboot.iot.DeviceDataCount FlinkTutorial-1.0-SNAPSHOT.jar
Apache Flink在工业物联网的应用场景中,已经证明了自己在高效流式计算方面的巨大能力。与研博工业物联网统一接入系统相结合,Flink在处理工业物联网数据时展现出了卓越的性能和实时分析的能力。这不仅使得企业能够获得更精确的数据洞察力,而且显著提高了生产效率和运营决策的反应速度。随着工业物联网技术的持续发展,Flink预计将在企业中持续担任关键角色,促进流式计算技术在工业领域的深入应用和广泛普及。
























