1、概述
在工业物联网系统中通常会由设备接入来针对某个区域内的监测完成智能化,设备在接入工业物联网统一接入系统之后会有携带的测点数据源源不断的上报实时监测数据到工业物联网统一接入系统,在某些场景下部分设备在上报数据之后还需要实时对其做预处理后存储。在处理这些流数据的解决方案中,通常会用到Kafka Stream 、Flink、Spark Stream等流处理框架和技术,但是这些流处理框架和技术同时也带来了高昂的开发和运维成本。这次给大家分享的是一款开源的时序库TDengine,它自带的流计算引擎提供了实时处理写入的数据流的能力,使用 SQL 定义实时流变换,当数据被写入流的源表后,数据会被以定义的方式自动处理,并根据定义的触发模式向目的表推送结果。
2、流计算介绍
在正式开始介绍流计算的具体使用方法前先介绍一下流计算使用过程中可能会用到的数据切分查询和窗口切分查询与流计算创建方式。
2.1、数据切分查询
当需要按一定的维度对数据进行切分查询,然后在切分出来的数据集中做后续计算时使用的数据切分子句。
partition by part_list;
语法介绍
1)part_list可以是某列、某个常量、某个标量函数和他们的组合;
2)partition by位于where之后;
3)partition by可以和窗口切分子句或group by一起使用。
举个例子,将t表的数据按照c1列进行分组,计算每个分组内c2的和:
select c1,sum(c2) from t1 partition by c1;
简单了解了数据切分查询之后,再介绍一下窗口切分查询。

2.2、窗口切分查询
当需要按照窗口切分方式进行聚合结果查询的时候可以使用窗口切分子句。
window_clause: {
SESSION(ts_col, tol_val)
| STATE_WINDOW(col)
|
INTERVAL(interval_val [, interval_offset]) [SLIDING (sliding_val)]
[FILL(fill_mod_and_val)]
| EVENT_WINDOW START WITH start_trigger_condition END
WITH end_trigger_condition
| COUNT_WINDOW(count_val[, sliding_val])
}
语法介绍
1)窗口子句位于数据切分子句之后,不能和group by子句一起使用;
2)窗口子句将数据按窗口进行切分,对每个窗口进行查询列表中的表达式计算,查询列表中的表达式只能包含:
常量;
窗口开始时间(_wstart)、窗口结束时间(_wend)、窗口持续时间(_wduration)三个伪列;
至少包含一个聚集函数;
包含上面表达式的表达式。
3)窗口子句中的where语句可以指定查询的起止时间和其他过滤条件。
窗口的种类有五种,分别为:
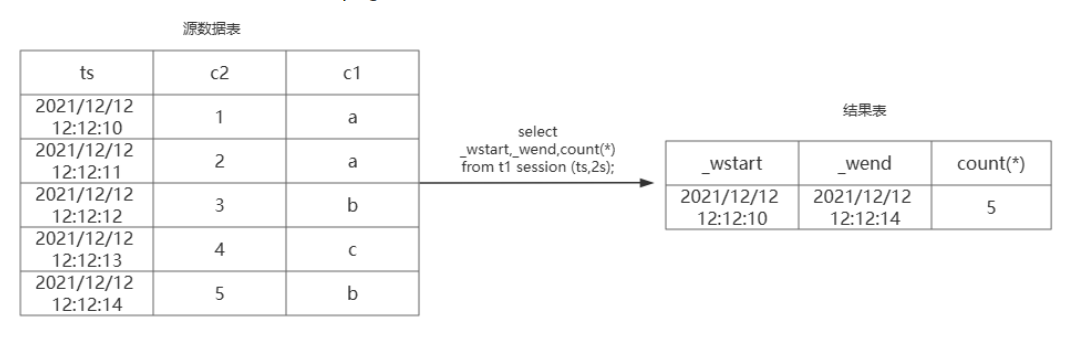
(1)SESSION:会话窗口;
话窗口根据记录的时间戳主键的值来确定是否属于同一个会话。
1):ts_col的值代表时间戳主键的列名;
2):tol_val的值代表时间间隔范围。
举个例子:
SELECT _wstart,_wduration,count(*) from t1 session (ts,2s);
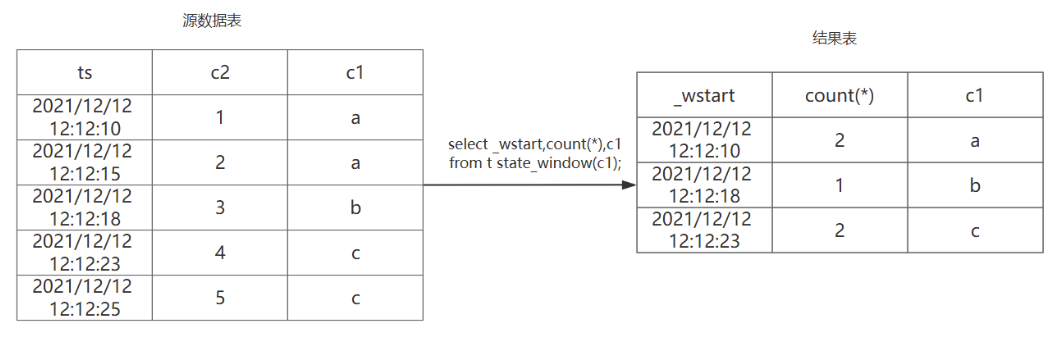
(2)STATE_WINDOW:状态窗口;
使用整数、布尔值或字符串来标识产生记录时候设备的状态量。产生的记录如果具有相同的状态量数值则归属于同一个状态窗口,数值改变后该窗口关闭。
select _wstart,count(*),c1 from t state_window(c1);
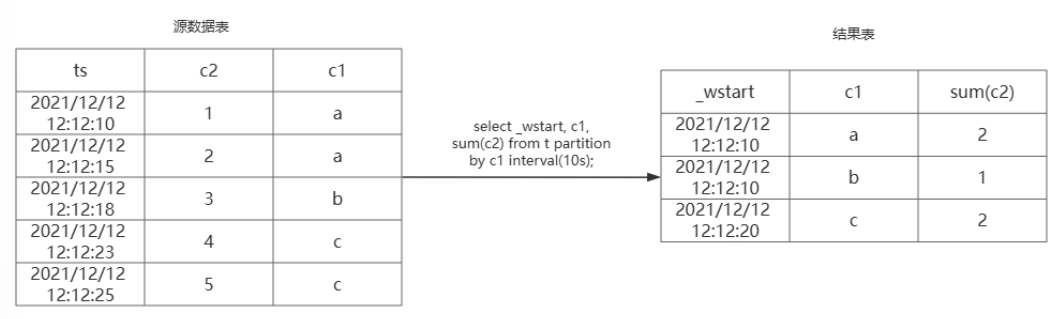
(3)INTERVAL:时间窗口;
时间窗口又分为了滑动时间窗口和翻转时间窗口;
1):interval_val的值代表具体的时间间隔;
2):interval_offset的值代表窗口的偏移量,必须小于interval_val的值;
3):sliding_val的值代表窗口滑动的时间间隔。
当interval_val的值和sliding_val值相等的时候滑动时间窗口也就是翻转时间窗口。
select _wstart, c1, sum(c2) from t partition by c1 interval(10s);
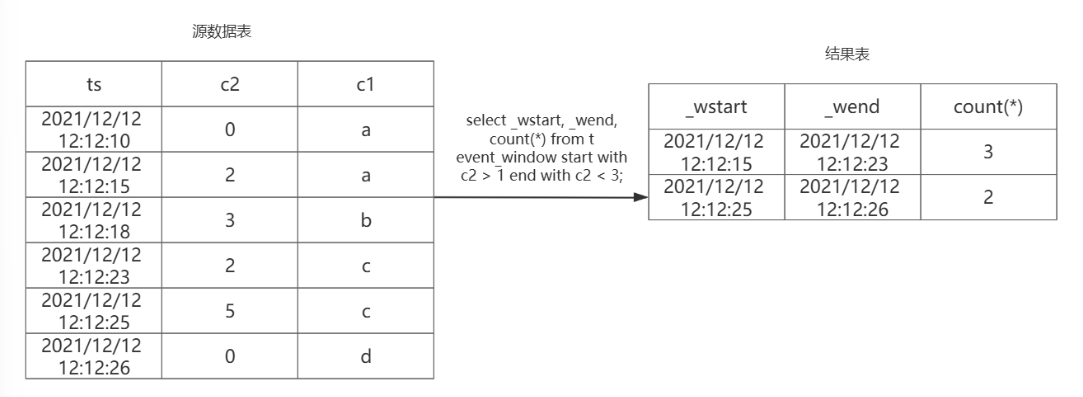
(4)EVENT_WINDOW:事件窗口;
事件窗口根据开始条件和结束条件来判断窗口,当start_trigger_condition满足时则窗口开始,当end_trigger_condition满足时窗口关闭,事件窗口无法关闭时,数据不会被输出。
select _wstart, _wend, count(*) from t event_window start with c2 > 1
end with c2 < 3;
(5)COUNT_WINDOW:计数窗口;
计数窗口按照固定的数据量来划分窗口,默认将数据按时间戳排序。
select _wstart,_wend,count(*) from t count_window(3);

2.3、流计算创建方式
CREATE STREAM [IF NOT EXISTS] stream_name [stream_options] INTO
stb_name[(field1_name, field2_name [PRIMARY KEY], ...)] [TAGS (create_definition
[, create_definition] ...)] SUBTABLE(expression) AS subquery
stream_options: {
TRIGGER [AT_ONCE | WINDOW_CLOSE | MAX_DELAY time] WATERMARK time
IGNORE EXPIRED
[0|1]
DELETE_MARK
time FILL_HISTORY [0|1]
IGNORE UPDATE [0|1]}
流计算触发模式
流计算触发模式可以通过TRIGGER指令指定,对于非窗口计算,流计算的触发是实时的;对于窗口计算,有3种触发模式,
1)AT_ONCE:写入立即触发;
2)WINDOW_CLOSE:窗口关闭时触发;
3)MAX_DELAY time:若窗口关闭则触发计算,若窗口未关闭且时长超过time指定的时间则触发计算。按照规定time的值不得小于5s。
流计算对于过期数据的处理策略
对于已关闭的窗口,再次落入该窗口中的数据被标记为过期数据。对于过期数据的处理方式由 IGNORE EXPIRED 选项指定:
1)增量计算,即 IGNORE EXPIRED 0;
2)直接丢弃,即 IGNORE EXPIRED 1:默认配置,忽略过期数据。
3、案例介绍
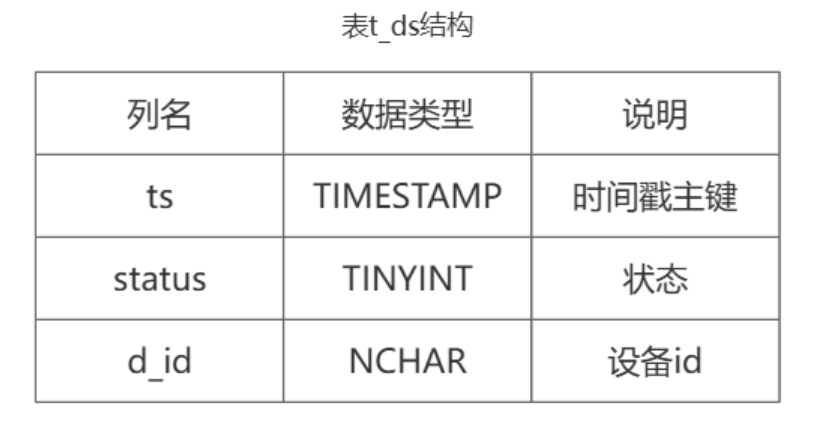
下面通过从表t_ds中统计设备的状态持续时间的一个小例子介绍流
3.1计算的使用方法:
3.2、流计算创建
CREATE stream IF NOT EXISTS t_ds_s TRIGGER at_once ignore expired 0
fill_history 1 INTO t_ds_s_t subtable(concat('t_ds_s_t',d_id))AS SELECT
_wstart,_wend,_wduration,count(*) AS cnt,d_id FROM t_ds PARTITION BY d_id,tbname
event_window START WITH status_text = 0 END WITH status_text = 1;
当数据流入源表之后,数据会被以定义的方式自动处理,并根据定义的触发模式向目的表推送结果。
3.3、结果查询
当有数据流入到表t_ds中时符合流计算中定义的窗口数据会实时的统计到流计算创建的表t_ds_s_t中。查询t_ds_s_t表,结果展示如下:
SELECT _wstart,_wend,_wduration,cnt,d_id FROM t_ds_s_t;
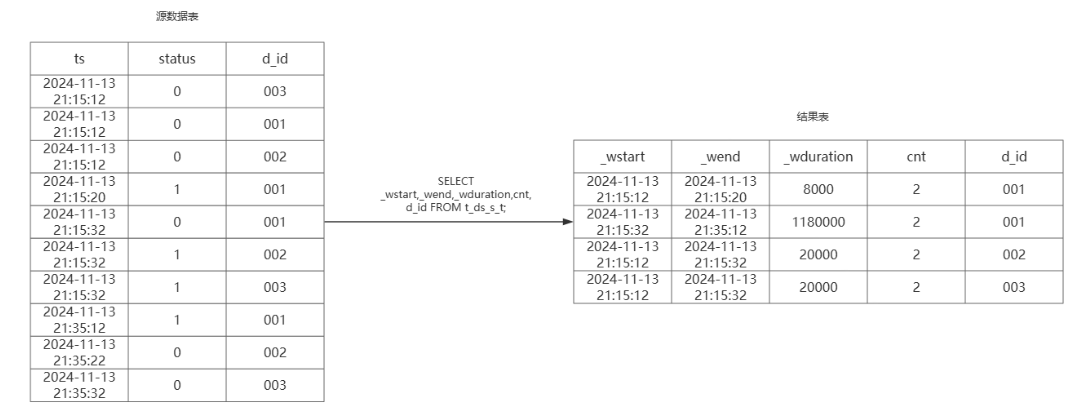
通过SQL得到已经统计完成的数据之后就可以针对设备状态变化做出一些灵活的展示,避免了再次引入其他流处理框架带来的额外的开销和成本。
4、尾声
在工业物联网应用场景中,在处理时序数据且不需要做过多的复杂处理时通过TDengine的流计算功能是一个轻量级且高效的解决方案,可以在开发过程中占用更少资源以更合适的方式处理流数据。
























